In de wereld van vandaag speelt data een centrale rol in hoe we beslissingen nemen, inzichten verkrijgen en innovaties doorvoeren. Data Science staat aan de frontlinie van deze ontwikkeling. Hierbij slaat het een cruciale brug tussen ruwe data en actionable insights. Deze discipline bevindt zicht op het snijvlak van statistiek, computerwetenschap, en domeinspecifieke kennis. Het stelt ons in staat om complexe vraagstukken te ontrafelen en patronen te ontdekken die anders verborgen zouden blijven. Met behulp van Python ontgrendelen datawetenschappers het potentieel van data door middel van het verzamelen, analyseren, en visualiseren ervan. Of het nu gaat om het voorspellen van consumentengedrag, het optimaliseren van bedrijfsprocessen, of het bijdragen aan wetenschappelijk onderzoek, de mogelijkheden zijn eindeloos.
De vraag naar deskundigen in dit veld groeit snel, aangezien organisaties van allerlei grootte erkennen hoe data-gedreven beslissingen hen een competitief voordeel kunnen bieden. Door de kracht van Data Science te omarmen, openen we de deur naar een toekomst waarin onze capaciteit om de wereld om ons heen te begrijpen en te verbeteren, exponentieel toeneemt.
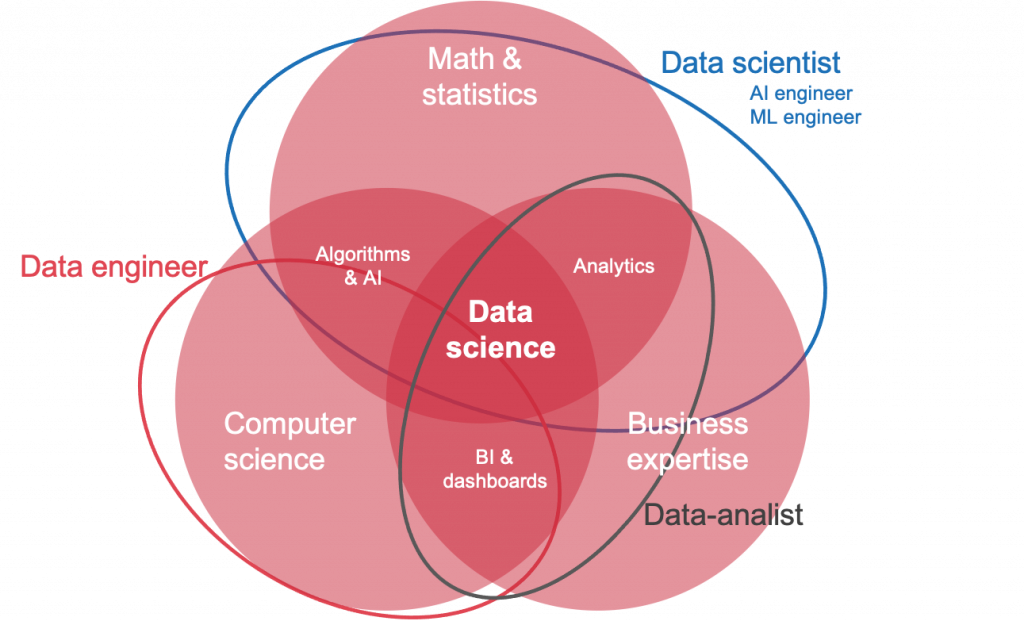
Wat is Data Science en waarom is het belangrijk?
Data Science, in zijn essentie, is een interdisciplinair veld dat gebruik maakt van wetenschappelijke methoden, processen, algoritmes en systemen om kennis en inzichten te verkrijgen uit zowel gestructureerde als ongestructureerde data. Maar waarom is dit nu zo belangrijk?
- Informeren van Besluitvorming: Data Science biedt de tools en technieken om gegevens te filteren, te analyseren en er zinvolle inzichten uit te halen. Dit stelt bedrijven in staat om geïnformeerde beslissingen te nemen.
- Innovatie en Ontwikkeling: Data Science speelt een sleutelrol bij het stimuleren van innovatie en ontwikkeling binnen bedrijven. Van het verbeteren van klantenservice tot het ontwikkelen van nieuwe producten
- Personalisatie: In de retail, marketing en vele andere sectoren maakt Data Science het mogelijk om klantgedrag te analyseren en gepersonaliseerde aanbiedingen of diensten te creëren. Dit leidt tot betere klanttevredenheid en loyaliteit.
- Efficiëntie en Optimalisatie: Door processen te analyseren en operationele inefficiënties te identificeren, kan Data Science helpen om operaties te stroomlijnen en de productiviteit te verhogen.
Data Science is onmisbaar in de omgang met geo-informatie en geodata. Het analyseren van ruimtelijke gegevens helpt namelijk bij stedelijke planning, milieubescherming, en het in kaart brengen van resources. De vaardigheden die je opdoet in de cursus Python en Datascience zullen je niet alleen in staat stellen om met deze data om te gaan, maar ook om inzichten te genereren die van invloed kunnen zijn op beslissingen op hoog niveau.
De rol van Python in Data Science
We hebben het belang van Data Science verkend. Laten we ons nu richten op de rol van Python in dit boeiende veld. Python heeft zich ontpopt als de lingua franca voor Data Science. Dit dankzij zijn eenvoud, flexibiliteit, en de rijke verzameling van data-analyse libraries die het biedt. Maar wat maakt Python zo onmisbaar voor datawetenschappers?
- Toegankelijkheid en Veelzijdigheid: Python’s eenvoudige syntaxis maakt het toegankelijk voor beginners. Dit terwijl zijn krachtige functies voldoen aan de behoeften van ervaren programmeurs.
- Rijk Ecosysteem: Python beschikt over een uitgebreid ecosysteem van libraries. Zoals NumPy voor numerieke berekeningen, Pandas voor data manipulatie, Matplotlib voor visualisatie, en Scikit-learn voor machine learning. Deze tools zijn essentieel voor het uitvoeren van data-analyse en het ontwikkelen van data science projecten.
- Ondersteuning voor Machine Learning en Deep Learning: Met libraries zoals TensorFlow en PyTorch is Python de voorkeurstaal voor het ontwikkelen van geavanceerde machine learning en deep learning modellen. Hierdoor wordt het mogelijk om patronen en inzichten uit grote datasets te halen.
De cursus Python en Datascience bij Geo-ICT maakt optimaal gebruik van Python’s mogelijkheden, door de deelnemers te leren hoe ze deze tools kunnen toepassen op real-world data-analyse uitdagingen. Door praktische ervaring op te doen met geo-informatie en geodata, kun je vaardigheden ontwikkelen die direct toepasbaar zijn in een breed scala van sectoren.
Python’s rol in Data Science kan niet worden overschat. Het dient als een krachtig instrument voor het ontsluiten van de potentie van data. Hierdoor zijn datawetenschappers in staat om voorspellende modellen te bouwen, inzichten te verkrijgen, en besluitvorming te ondersteunen met kwantitatieve bewijzen. Of je nu net begint met programmeren of al ervaring hebt, Python biedt een solide basis voor een carrière in Data Science. Deze cursus is je springplank naar succes in dit dynamische veld.
Wat ga je leren in de Cursus Python en Datascience
Programmeren met Python: basis tot geavanceerde technieken
Als je duikt in de wereld van programmeren met Python, begin je aan een reis van eenvoudige scripts tot complexe applicaties. Python staat bekend om zijn eenvoudige syntax, die het voor beginners gemakkelijker maakt om te starten. Het is ontworpen om leesbaar en duidelijk te zijn, met een focus op zichtbaarheid van de code. Dit bevordert niet alleen het leerproces maar maakt ook samenwerking en onderhoud gemakkelijker.
Wanneer je je kennis verdiept, zul je ontdekken dat Python ondersteuning biedt voor verschillende programmeerstijlen – objectgeoriënteerd, procedureel en functioneel programmeren, waardoor het een flexibele keuze is voor veel soorten projecten. Deze veelzijdigheid trekt een breed scala aan ontwikkelaars aan, waardoor de taal levendig en constant in ontwikkeling blijft.
Python’s rijke ecosysteem van libraries en frameworks stelt je in staat om snel te werken aan een reeks projecten, van webapplicaties tot data-analyse en machine learning. Met frameworks als Django en Flask kun je efficiënte webapplicaties ontwikkelen, terwijl libraries als TensorFlow en NumPy essentieel zijn voor geavanceerde data-analytische projecten en machine learning.
Naarmate je vordert, zul je geavanceerde technieken leren zoals:
- List comprehensions voor efficiëntere loops,
- Decorators om functies te verrijken zonder hun code te wijzigen,
- Lambda functies voor anonieme functie-uitdrukkingen,
- Objectgeoriënteerd programmeren (OOP) voor een betere codeorganisatie en herbruikbaarheid.
Je zult ook leren over het belang van code- en versiebeheer met tools zoals Git, die essentieel zijn voor samenwerking in teamverband en het beheren van projecten naarmate ze groeien. Package management, met tools zoals Poetry, helpt bij het beheren van afhankelijkheden en het verzekeren van de consistentie van projecten.
Data-analyse en visualisatie: werken met Pandas en Matplotlib
Bij het betreden van de wereld van data-analyse met Python, zijn Pandas en Matplotlib twee onmisbare tools in je arsenaal. Pandas is een krachtige library voor data-manipulatie en analyse, ontworpen om het werken met tabulaire data, zoals je zou vinden in spreadsheets of databases, intuïtief en efficiënt te maken. Matplotlib, aan de andere kant, is de go-to library voor data-visualisatie in Python. Hiermee kun je een breed scala aan statische, geanimeerde en interactieve visualisaties maken.
Werken met Pandas
Pandas biedt datastructuren zoals DataFrames en Series die het eenvoudig maken om data te laden, te verwerken, te analyseren en te visualiseren. Enkele kernfunctionaliteiten omvatten:
- Het eenvoudig inlezen en schrijven van data uit verschillende bestandsformaten zoals CSV, Excel en SQL databases.
- Uitgebreide functies voor het manipuleren van data, waaronder filteren, sorteren, en groeperen.
- Krachtige tools voor het uitvoeren van statistische analyses en het werken met tijdreeksen.
Visualisatie met Matplotlib
Matplotlib stelt je in staat om de inzichten in je data tot leven te brengen via visualisaties. Of je nu lijndiagrammen, staafdiagrammen, scatterplots of complexe contourdiagrammen nodig hebt, Matplotlib biedt de flexibiliteit om deze te creëren. Het werkt hand in hand met Pandas, waardoor je direct vanuit DataFrames kunt plotten.
Verdieping en Toepassingen
- Geavanceerde Visualisaties: Naast basisdiagrammen, kun je met Matplotlib ook geavanceerde visualisaties creëren. Zoals 3D-diagrammen en geografische kaarten.
- Data Cleaning en Voorbereiding: Voordat je tot visualisatie overgaat, helpt Pandas je bij het schoonmaken en voorbereiden van je data. Dit is een cruciale stap in elk data-analyseproces.
- Exploratieve Data Analyse (EDA): Met Pandas en Matplotlib kun je diep in je data duiken, patronen ontdekken, hypotheses testen en cruciale zakelijke inzichten verkrijgen.
De combinatie van Pandas voor data-analyse en Matplotlib voor visualisatie biedt een krachtige toolset voor data-analisten en wetenschappers. Of je nu werkt aan financiële modellering, wetenschappelijk onderzoek, of het analyseren van webverkeer. Deze libraries stellen je in staat om inzichten uit je data te halen en deze op een begrijpelijke manier te communiceren.
Machine Learning: inleiding tot Scikit-Learn
Machine learning (ML) is een krachtig instrument in de hedendaagse data-analyse en kunstmatige intelligentie. Hierbij is Scikit-Learn een van de meest populaire en gebruiksvriendelijke bibliotheken voor ML in Python. Scikit-Learn biedt toegang tot een breed scala aan algoritmen en tools voor zowel supervisie als ongesuperviseerde leermethoden. Hiermee kun je effectief patronen identificeren en voorspellingen doen op basis van je data.
Belangrijke Componenten van Scikit-Learn
- Datasets: Scikit-Learn bevat enkele standaard datasets, zoals de iris en digits datasets voor classificatie en de diabetes dataset voor regressie. Deze kun je gebruiken om ML-concepten te oefenen en te begrijpen.
- Estimators: Voor het uitvoeren van ML-taken, introduceert Scikit-Learn het concept van ‘estimators’. Een estimator is een Python object dat de methoden
fit(X, y) en predict(T) implementeert voor het leren van data en het doen van voorspellingen.
- Model Selectie: Scikit-Learn biedt tools voor modelselectie, zoals grid search en cross-validation, om de beste parameters voor je model te vinden en de prestaties ervan te evalueren.
Praktische Toepassingen
Scikit-Learn wordt breed ingezet voor verschillende toepassingen, waaronder maar niet beperkt tot:
- Classificatie: Het identificeren van de categorie waartoe een object behoort. Dit wordt veel gebruikt in spamdetectie en beeldherkenning.
- Regressie: Het voorspellen van een continue waarde die geassocieerd wordt met een object, zoals aandelenprijzen of geneesmiddelreacties.
- Clustering: Het automatisch groeperen van vergelijkbare objecten in sets, wat nuttig kan zijn in klantsegmentatie en het groeperen van experimentresultaten.
Aan de slag
Om te beginnen met Scikit-Learn, moet je vertrouwd raken met de basisstappen van het laden van een dataset, het kiezen van een estimator (model), het trainen van dit model op je data, en het maken van voorspellingen. Het proces begint met het importeren van de benodigde modules en het laden van je dataset. Vervolgens selecteer je een model en pas je dit aan je data aan met de fit methode. Ten slotte gebruik je het getrainde model om voorspellingen te doen op nieuwe, ongeziene data.
Scikit-Learn’s design is gestructureerd en intuïtief, waardoor het een uitstekend startpunt is voor iedereen die geïnteresseerd is in machine learning. Of je nu een beginner bent of een ervaren datawetenschapper, de bibliotheek biedt een solide basis om je vaardigheden te ontwikkelen en uit te breiden.
Voor meer gedetailleerde informatie en tutorials kun je de officiële Scikit-Learn documentatie raadplegen. Deze bevat uitgebreide gidsen en voorbeelden om je te helpen bij het navigeren en toepassen van machine learning met Scikit-Learn.
Waarom kiezen voor onze Cursus Python en Datascience?
Kiezen voor onze cursus Python en Datascience bij Geo-ICT betekent een diepgaande duik in de essentiële tools en technieken voor data-analyse en machine learning. Deze cursus, verdeeld over vier dagen, combineert theorie en hands-on oefeningen om je vaardigheden in Python-programmering, data-manipulatie met Pandas, numerieke berekeningen met NumPy, en datavisualisatie met Matplotlib te ontwikkelen. Je leert ook praktische toepassingen van machine learning met de Scikit-Learn bibliotheek. Het curriculum is ontworpen om je niet alleen kennis bij te brengen, maar ook om je in staat te stellen deze kennis toe te passen in je eigen projecten en werkzaamheden, met nadruk op zelfstandige analyses en het gebruik van Jupyter Notebooks voor een interactieve ontwikkelervaring.